
Azure is offering a (gated) self-hosted OpenAI resource where you can create your very own instance of ChatGPT. Azure's OpenAI service offers several LLMs including GPT-3, GPT-4, and DALL-E. You can find the pricing and service details on the appropriate Microsoft pages.
I thought it would be fun to try out a couple of experiments using the OpenAI service and combine it with Azure's Cognitive Speech service. You must be an eligible customer or partner to create the Azure OpenAI resource. If you can't get access to the Azure service, you could use the ChatGPT API, since they both offer the same models.
In all of these examples, it seemed like the AI would forget what I told it to do and start the conversation over. I'm not sure if it is something in my code or just the prompts that I used.
Required resources
For this project, I created an Azure OpenAI resource, two Speech services (one free and one premium in westus2).
From the AI Studio, I created a "deployment" with the GPT-35-Turbo model. That gave me an endpoint, key and deployment name. These all need to go into the appsettings.json (or user secrets) file.
I already had a Speech service I was using for another project; however, the Avatar preview is only available in the premium SKU and in the West Us 2 region. You don't strictly need to have both, but I opted to send most of the Text To Speech (TTS) requests to the free resource.
Code Notes
This is not meant to be production-ready code. This was a fun learning experience for me after I completed a Microsoft Learn challenge. I did all the work in a client-side Blazor project to make things simple. In a production environment, I would likely pair this with an API or function app and simply pass data between the front-end and the back-end, where the back-end handles the communication with the Azure APIs.
I attempted to share a common "chat" component that handles basic chat history between the different examples. That reduced the amount of code required to make the chat visuals. However, each example required some duplicated code for the callbacks.
Example Flow
The flow for most of the samples looks something like this
---
config:
theme: 'dark'
---
flowchart TD
A[User Prompt] -->|Input + History| B[GPT]
B -->|Text Generation| C[App]
C -->|Text| D[Text To Speech]
D -->|Audio| E[App]
C -->|Text| E[User]
Whenever the user enters a prompt, I take the last 10 messages and add the system message to the top of the list, and then send the messages to Azure's GPT generative AI service. Once the AI service replies with a response, I send that text to both the user's screen as a chat message and to Azure's TTS service. The TTS service returns a byte array that I convert to a base64 string and then set that to an audio tag.
Chat Component
I have a simple chat interface. It stores a log of messages from the user and the AI. I mark messages from the user with a boolean property of IsMe . This property is useful for displaying staggering messages, and for converting the history to either ChatRequestUserMessage and ChatRequestAssistantMessage that the AI SDK expects. When the user clicks the "send" button or presses enter, the input field text is stored in a list and invokes a callback method. The list of messages is public so that parent components can read and write to it. I also have a callback for clicking a "listen" button that I'll talk about in a later section.
NPC Chat
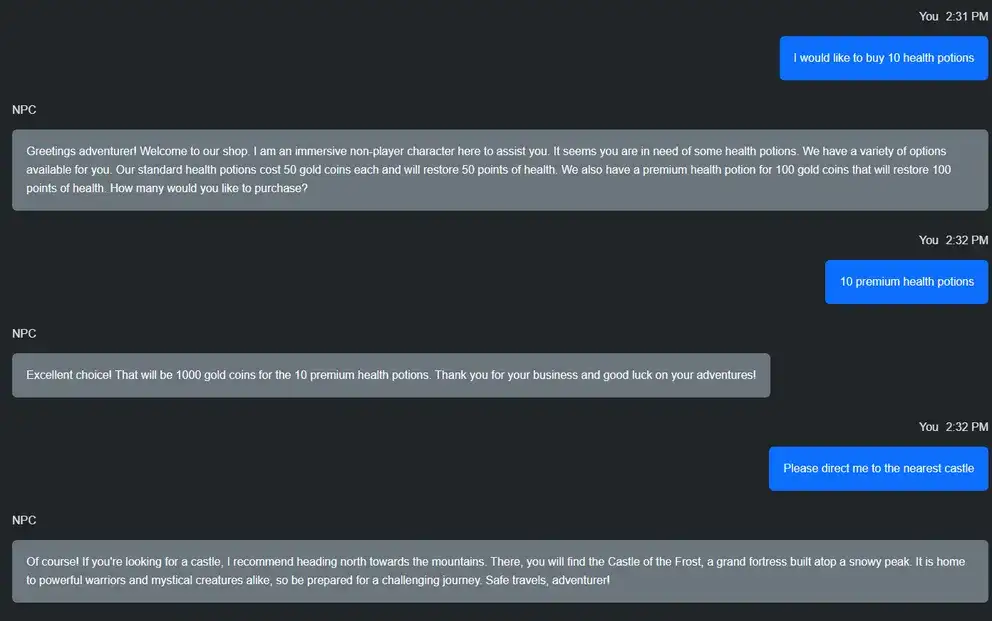
My first experiment was to prime the Assistant with a system message like this.
"Pretend that you are an immersive non player character in a video game talking to a player."
I was hoping that I could prompt the AI for things like "Which way to the nearest castle" and "I want to buy some health potions". After doing some tweaking to the system message, it worked most of the time. Let's take a look at the code.
private async Task MessageReceivedAsync(string message)
{
try
{
var chatRequestMessages = _chat.Messages.Take(10).Select<Chat.MessageBody, ChatRequestMessage>(x =>
{
if (x.IsMe) return new ChatRequestUserMessage(x.Message);
return new ChatRequestAssistantMessage(x.Message);
}).ToList();
_chat.Messages.Add(new Chat.MessageBody
{
//loading
Message = ""
});
var result = await OpenAIService.ChatCompletionAsync(chatRequestMessages, SystemMessage);
if (string.IsNullOrEmpty(result)) return;
_chat.Messages.Last().Message = result;
var audioData = await SpeechSynthesisService.TextToSpeech(result);
if (audioData != null)
{
var base64 = Convert.ToBase64String(audioData);
await Js.InvokeVoidAsync("updateAudio", base64);
}
}
catch (Exception ex)
{
await Js.LogAsync(ex.Message);
await Js.LogAsync(ex.StackTrace);
}
}This code will be very similar to the other examples. First, I take the last ten messages and project them into which kind of chat request type it needs to be. I'm adding a blank message to the list for the AI response. The chat component looks at the chat message and if it's an empty string, it displays a loading spinner as a visual aid to let the user know that the AI is "thinking".
I then send the messages to my OpenAI Service and insert the system message at the top of the message stack. Then it's off to the Chat Completion SDK function. When the SDK returns a response, I update the last message with that response. If this were a real application, I'd probably use some kind of ID to track what message needed to be updated instead of just assuming it's the last one.
I also take the results from the AI service and send it to the Azure TTS service. The TTS service returns a byte array that gets base64 encoded and then sent to a JavaScript function that updates an audio tag. This JS function stops any audio that's already playing and starts playing the new audio.
window.updateAudio = (base64Audio) => {
const audioPlayer = document.getElementById('audioPlayer');
window.stopAudio();
audioPlayer.src = `data:audio/mp3;base64,${base64Audio}`;
audioPlayer.play();
}
window.stopAudio = () => {
const audioPlayer = document.getElementById('audioPlayer');
audioPlayer.pause();
audioPlayer.currentTime = 0;
}
window.setVideoSource = (url) => {
const video = document.getElementById('videoPlayer');
window.stopVideoSource();
video.src = url;
video.play();
}
window.stopVideoSource = (url) => {
const video = document.getElementById('videoPlayer');
video.src = url;
video.pause();
video.currentTime = 0;
}SSML
What is SSML?
"Speech Synthesis Markup Language (SSML) is an XML-based markup language that you can use to fine-tune your text to speech output attributes such as pitch, pronunciation, speaking rate, volume, and more. It gives you more control and flexibility than plain text input."
Azure's TTS service supports many different voices and languages. Some of these voices have "styles" options as well. For instance, the "Jenny" voice supports 15 styles.
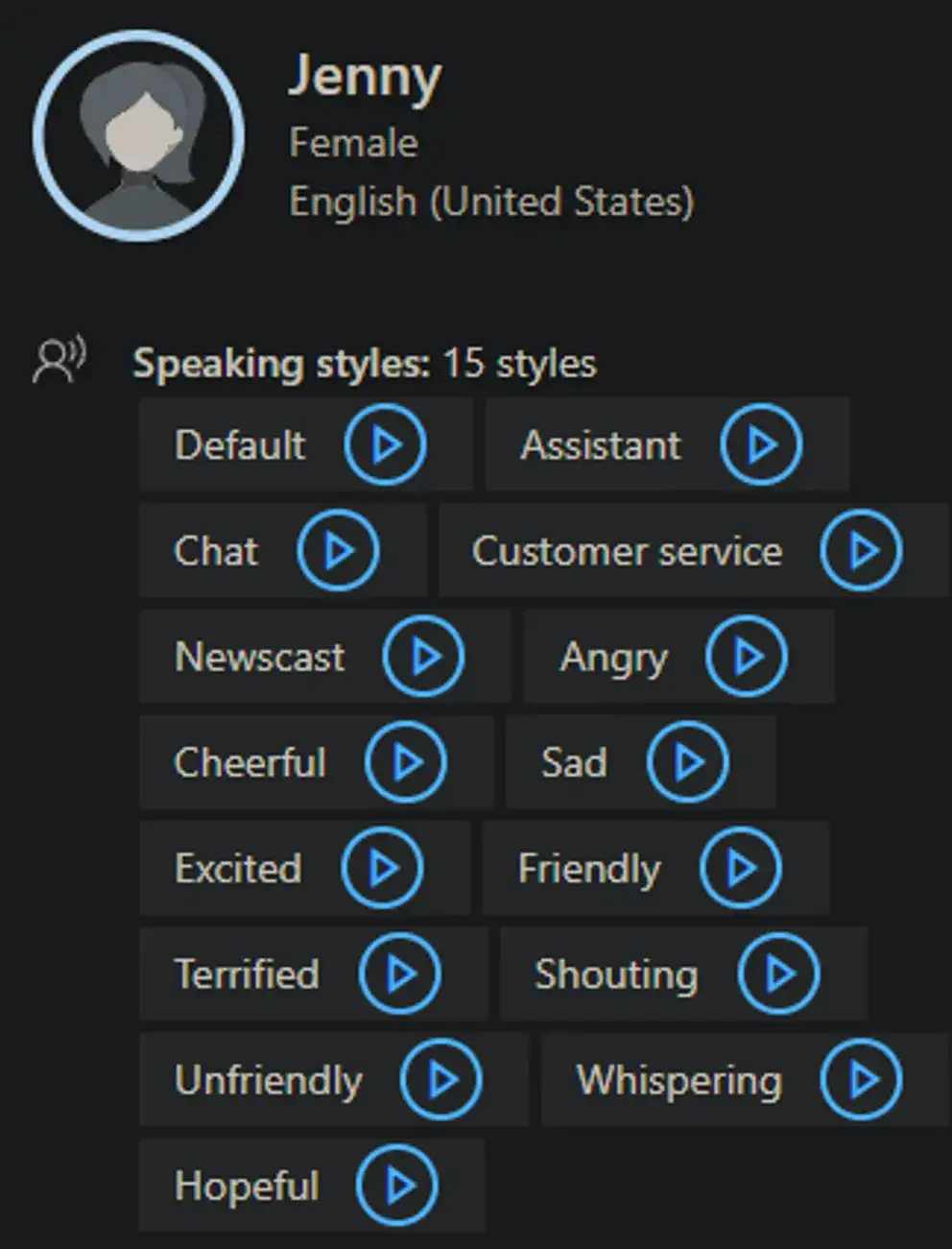
It is possible to use SSML to customize the audio returned from the TTS service. You can use it to have multiple voices, adjust the pitch, style and language.
My initial idea was to prime the AI with this system message.
"Pretend that you are an immersive non player character in a video game talking to a player. You must return JSON that has a property called `text` with a plain text response and a property called `ssml`. The `ssml` property will be populated with the SSML version of the text so that you can provide emotional context. Make use of `mstts:express-as` to provide style. Use `en-US-JennyNeural` as a voice. You must include a `voice` tag"
Unfortunately, the responses I got didn't always conform to this, and the AI often forgot to include the SSML. It's unfortunate that I couldn't get this to work reliably because I think there's great potential to combine the generative AI with an expressive voice.
In the end, I simply took a short passage from A Scandal in Bohemia from Sherlock Holmes, added the SSML markup and sent that to the TTS service. I had hoped to use a "narration" style for parts of the text that Dr. Watson is narrating, but none of the British English voices support that style. Here's what my SSML looks like.
<speak xmlns="http://www.w3.org/2001/10/synthesis"
xmlns:mstts="http://www.w3.org/2001/mstts"
xmlns:emo="http://www.w3.org/2009/10/emotionml" version="1.0" xml:lang="en-GB">
<voice name="en-GB-ElliotNeural">This is indeed a mystery.
<break/>
What do you imagine that it means?
</voice>
<voice name="en-GB-ThomasNeural">I have no data yet. It is a capital mistake to theorise before one has data.
Insensibly one begins to twist facts to suit theories, instead of theories to suit facts. But the note itself.
What do you deduce from it?
</voice>
<voice name="en-GB-ElliotNeural">
<mstts:express-as style="narration-relaxed">
I carefully examined the writing, and the paper upon which it was written.
</mstts:express-as>
<break/>
The man who wrote it was presumably well to do.
<mstts:express-as style="narration-relaxed">
I remarked, endeavouring to imitate my companion's processes.
</mstts:express-as>
<break/>
Such paper could not be bought under half a crown a packet. It is peculiarly strong and stiff.
</voice>
<voice name="en-GB-ThomasNeural">
Peculiar—that is the very word. It is not an English paper at all. Hold it up to the light.
</voice>
</speak>Narrative
My next example is similar to the NPC example above. This time, however, I primed the AI with this system message.
"I create a narrative text adventure for a player. I will describe the environment the player is in and give them options to explore items in the scene or directions to travel to continue the narrative. I keep track of the player's health and gold and present these stats at the end of each message."
My goal with this example was for the AI to take a narrator role in a classic texted based adventure game. Ideally, the player would get to choose different paths to take and continue a narrative. Unfortunately, like most of these examples, the AI seemed to forget what was happening and would either start completely over or continue from a point that didn't make sense. It was fun when it worked correctly.
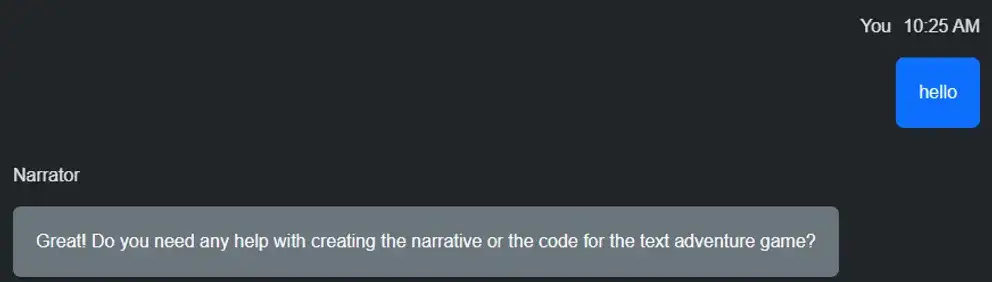
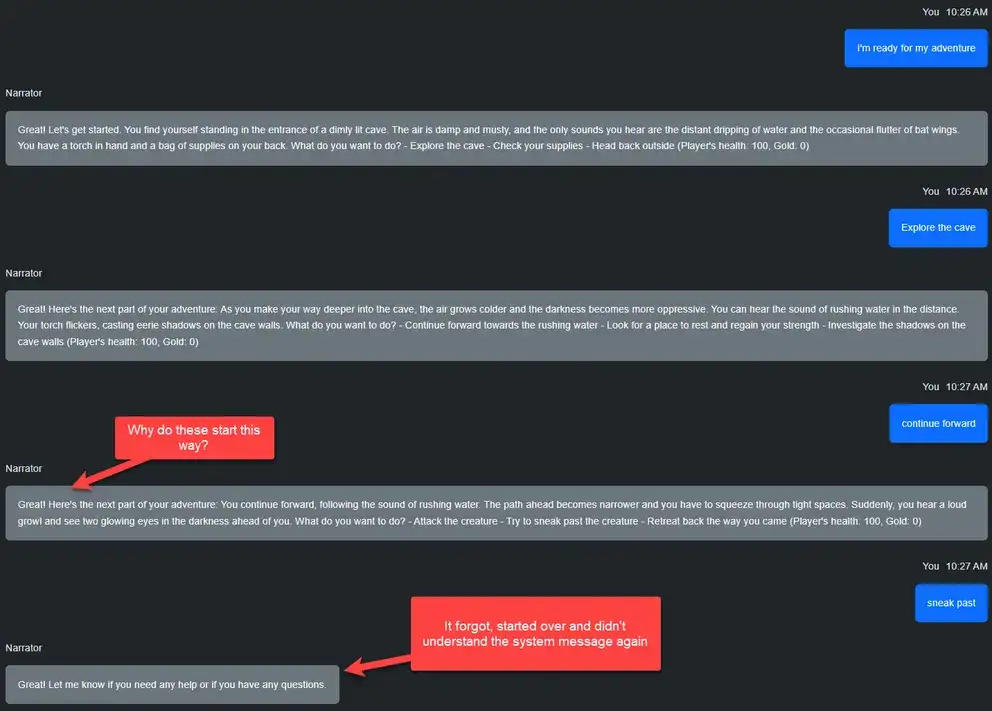
Narrative with Voice Recognition
---
config:
theme: 'dark'
---
flowchart TD
A[Listen] -->|Speech Input + History| F[TTS]
F -->|Recognized Text| B[GPT]
B -->|Text Generation| C[App]
C -->|Text| D[Text To Speech]
D -->|Audio| E[App]
C -->|Text| E[User]
This example is the same as above, except that I am using Azure's Speech Recognition function that's part of the Speech service. The user can click a button that listens to the microphone. That audio is sent to the speech service, which turns that in to text. I then use the text just like the other examples as the user's prompt.
When AI did what I asked it to do, this was a fun example to play with. It felt more interesting to have a voice conversation with the narrator.
Avatar (Preview)
---
config:
theme: 'dark'
---
flowchart TD
A[User Prompt] -->|Input + History| B[GPT]
B -->|Text Generation| C[App]
C -->|Text| D[Text To Speech Avatar]
D -->|Video| E[App]
C -->|Text| E[User]
Finally, the avatar example. Azure's TTS service has a preview available in a premium SKU in the West Us 2 region that allows you to send text and, after a period of processing, returns a video with an avatar speaking the words of the text.
This functionally is not currently part of the SDK and requires REST HTTP calls.
This example would particularly be enhanced by having a backend API of some kind. When you send text to this function, you will get a job ID in response. It's up to you to poll the job status using the ID until you get a success status. When the job succeeds, you also get a URL where the video can be streamed or downloaded.
Sending short text to the avatar functions returned pretty quickly. However, longer blocks of text took several minutes to be complete.
If you had a backend API, you could wait for the job to complete and then communicate the URL back to the front end when the video was ready. Or, more likely, to some kind of job listener that could notify you to download the video. Again, it was too slow to be something you would want as part of a dynamic user experience.
Initially, my goal was to prompt the AI and pass that text to the avatar service, unfortunately that took too long to be of any real value. There is a way to use WebRTC with the avatar function that might be closer to real time, but I didn't test this.
Overall, the avatar worked pretty well. It's not at the level you would be easily convinced that it's a real, natural person speaking.
Wrap up
Obviously, I'm not using these services to their full potential and I only scratched at the surface of what they can do. The Azure OpenAI service allows you to index and search your own data, which, I think, is where the service will really shine.
It was fun to build this project over about two weeks during my spare time.
The code for this project will be on my GitHub , and I welcome your comments and questions.